-
根因分析:一招挖出影响质量的隐形因果链
每天面对成千上万的检验数据,你的工作是不是也变成了“为了做SPC而做SPC”?
月底算一算CPK,看看控制图上有没有飘红的异常点……但真遇到产品良率波动、性能不稳,老板在会上追问“到底是前段哪个工艺参数出了问题”时,很多时候还是只能靠车间老专家的经验去猜、去试错。
既然企业已经沉淀了海量的检测数据,我们自然不能让它们只停留在“出报表”的层面。
今天,我们不谈枯燥的统计学公式,来聊一个非常实用、但绝大多数质量人都忽略了的高阶实战技巧——如何从现有的历史数据中,挖出工艺参数之间的“隐形因果关系”?
一、 质量分析的盲区:被忽略的“时间差”
在制造业现场,我们经常会带着一种“同步思维”去排查问题:
假设前端有一个关键控制点 X(比如反应罐温度、主轴转速),末端有一个质量结果 Y(比如产品透明度、表面粗糙度)。我们理所当然地认为:现在的 X,决定了现在的 Y。
如果把这两组数据拉出来做个散点图,排成一条明显的斜线,那就是标准的同步回归分析。你能轻松得出结论:温度每升高1度,透明度下降2%。
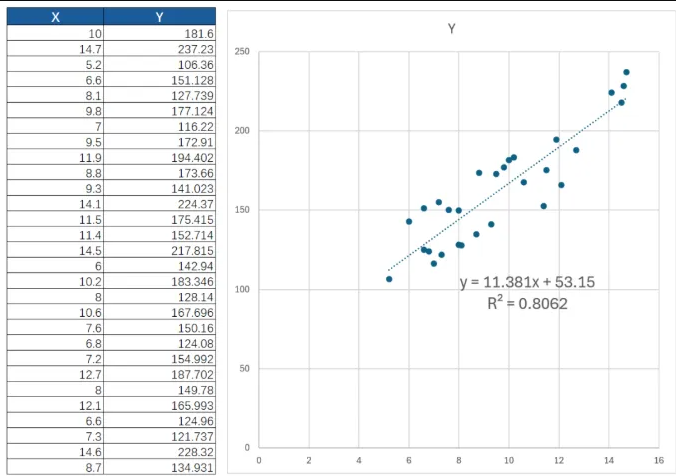
但在真实的物理车间里,工艺传导是有“坑”的。
很多时候,你把收集到的数据一一对齐对比,发现散点图乱七八糟,完全找不出规律。难道是这俩参数没关系?
其实未必。真正的“真凶”可能戴上了“滞后(Lag)”的面具。
举个典型的化工或流体制造场景:
10:00 调整了前端搅拌罐的温度,但经过管道传输和反应时间,受这个温度影响的产品,可能是 10:05 才流出检测口的。
如果你硬拿 10:05 的温度去和 10:05 的透明度做对比,当然毫无规律可言。这就叫滞后相关性。影响当下产品质量的,往往是两三个批次、甚至十几分钟前的关键参数。
二、 Excel排查实录:原理都懂,但操作“想死”
如果你想用表格去证实这种“滞后关系”,操作会非常痛苦。
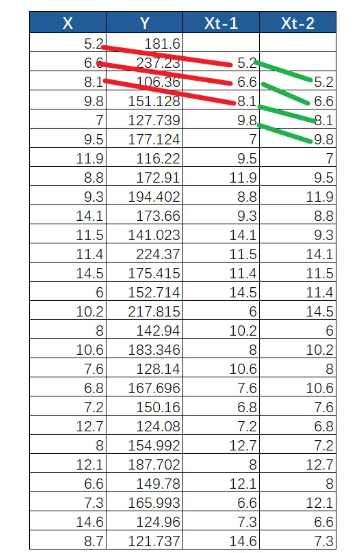
传统的做法是:打开Excel,先把 X(温度)和 Y(透明度)并排放在一起做散点图。如果看不出规律,你就得开始手动“错位”:
1. 把 X 这一列数据,整体往下挪一格(假设这叫滞后1期,即 t-1),再生成一次散点图看趋势。
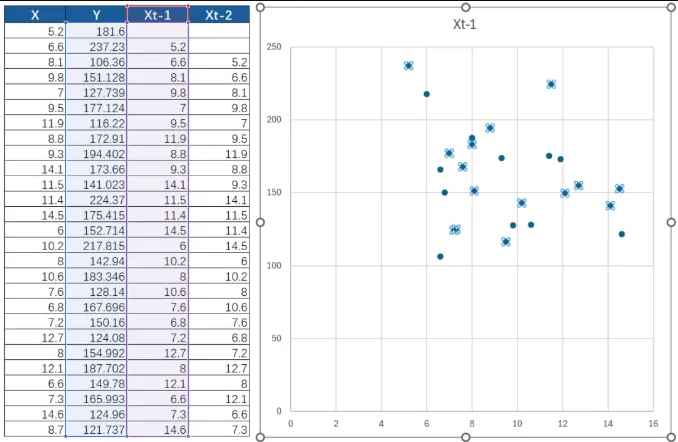
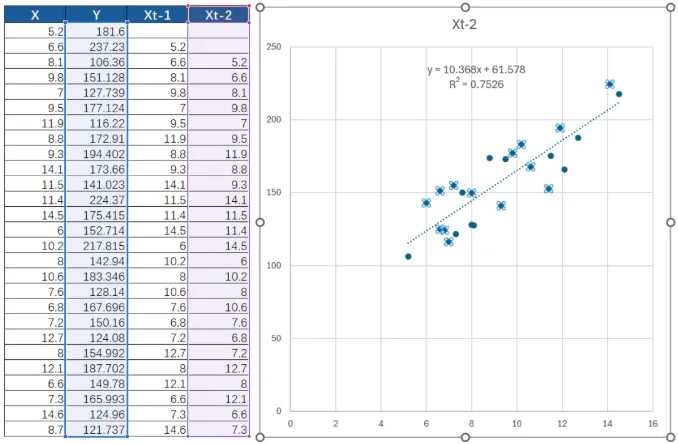
2. 还是不行?那就再往下挪一格(滞后2期,即 t-2)。
3. 突然,当你挪到第二格的时候,图表上的散点奇迹般地集中在了一条直线附近——破案了!关系找到了!
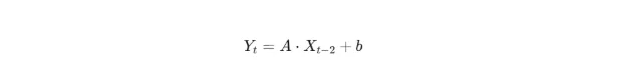
痛点在哪里?
逻辑虽然行得通,但现实生产中,你面对的往往不是 1 个参数,而是 10 个、甚至 50 个潜在影响因子。难道你要在表格里,把几十个参数各自挪动十几次去“试错”吗?这显然不符合工业数据分析的效率要求。
三、 降维打击:让数据自己“开口说话”
真正成熟的过程质量控制(SPC)体系,早就跨过了“看图报警”的阶段,进入了“智能根因溯源”的维度。在这个维度里,最硬核的优势就是:打破盲猜,用算力代替人力进行海量排查。
现实生产中,当末端良率波动时,你根本不知道是谁惹的祸。是前段的温度?中段的压力?还是辅料的浓度?
没关系,在我们日常使用的高阶质量分析工具中,这变成了“点点鼠标”的事:
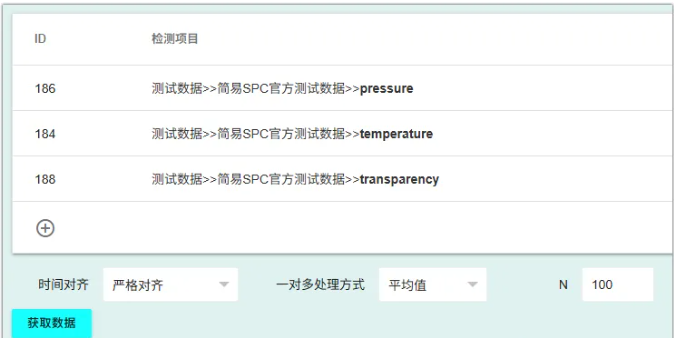
1. 圈定海量嫌疑范围,一键撒网
你不必再像用Excel那样一对一去试。
直接在系统中把你认为“可能相关”的几十个检测项目(无论是DCS设备数据还是检验记录)全部勾选上,并设定一个滞后范围。
2. 1秒生成“因果热力图”,谁影响谁一目了然
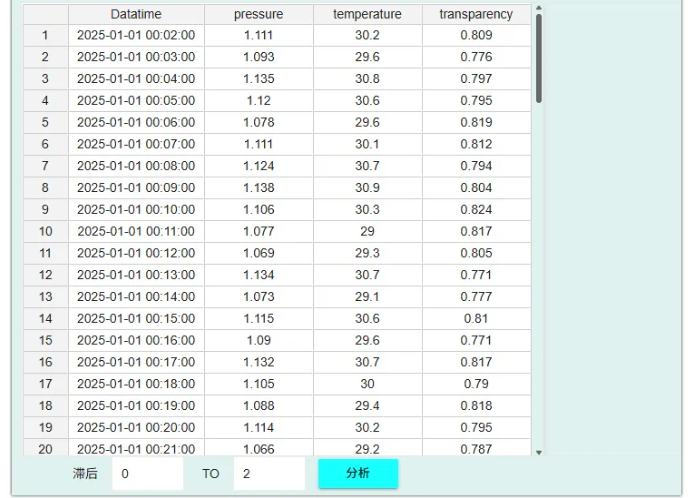
点击分析,只需短短 1秒钟,系统在后台完成了数万次的错位比对和相关性计算,直接输出一张花花绿绿的相关系数热力诊断矩阵图。
你只需盯着颜色最深(最红或最蓝)的交叉点看。它不仅告诉你“A影响了B”,更能帮你梳理出一条清晰的传导链:“谁影响了谁,谁又在两期之后影响了后面的谁”。
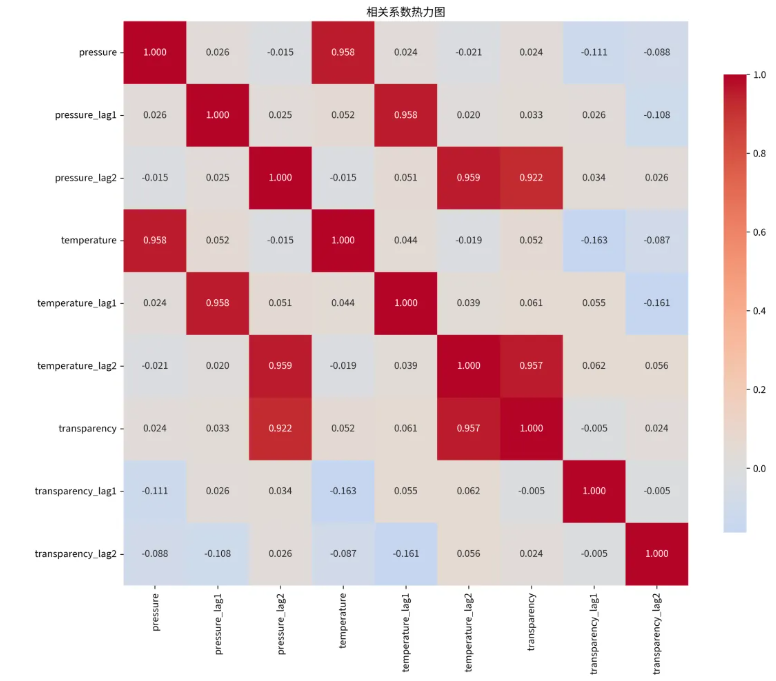
比如图上清晰显示:透明度(t) 与 同期的温度(t) 毫无关联。但顺着看,透明度(t) 与 温度(t-2) 的交叉点相关系数高达 0.957!
3. 从找规律到提质增效
这就实锤了:产品透明度就是受“两分钟前”的温度影响。
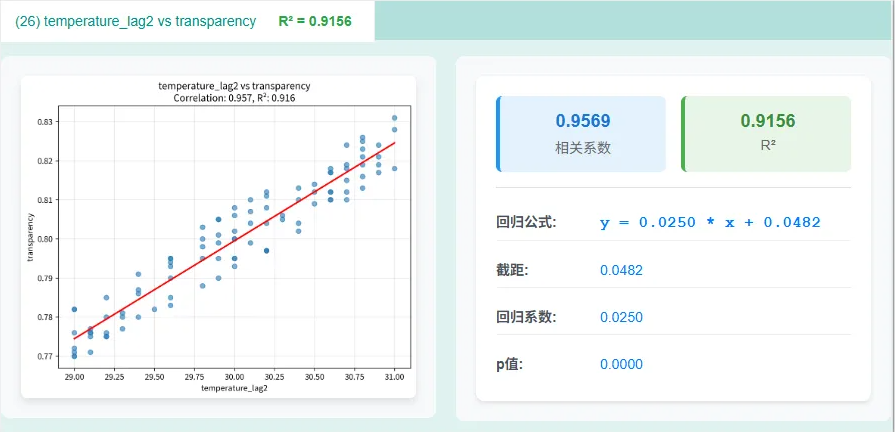
x是t-2期的温度
y是t期透明度
现在的温度增加1度,两个周期后(t+2)的温度(Yt+2)就增加0.025
过去,产线上出了异常,几个老工程师可能要开会扯皮一星期才能定位原因;现在,1秒钟就能揪出元凶。系统甚至会直接给出回归控制模型——操作工再也不用凭感觉微调,只要看着前段参数的波动,就能精准预测并干预当下的产品质量,把废品扼杀在摇篮里。
四、 写在最后
质量管理有一句老话:“检验只能挑出次品,控制才能制造良品。”
真正有价值的数据挖掘,不是追求算法有多花哨,而是能不能切实解决现场排查慢、找因难的盲点。
跳出单一参数的控制图,引入“时间差变量”,进行大批量参数的滞后回归分析,是彻底唤醒车间沉睡数据的关键一步。
下次再遇到“找不到原因”的质量波动,不妨放下手里手动错位的表格,用现代化的分析系统,1秒钟给你的产线做一次深度的“关系体检”吧。
本页面文章与公众号同步。

微信扫码关注