-
SPC成败关键之一:数据结构
企业实施SPC失败的根源往往不是统计方法错误,很多是因为底层数据结构问题导致的。孤立的测量值毫无工业价值。合格的SPC是必须在检测发生时,将零件测量值、设计公差与制造追溯信息(如工单、设备、模具)进行都进行记录,SPC系统才能实现异常追溯、维度分析。否则SPC软件固然能画出精美的图表,但统计过程控制却始终游离于核心业务之外。 孤立数据毫无作用
很多人以为实施 SPC 就是将检测设备导出的 CSV 或是手工记录的检验数值导入软件进行运算。在真实的工业现场,一个孤立的尺寸测量值(例如 12.09mm)如果剥离了上下文,其诊断价值几乎为零。
这 12.09mm 属于哪个零件批次,哪个工单号?对应 BOM 中的哪个产品特性?是在哪条产线的哪个工位加工的?使用了哪台加工设备和哪套模具?是来自哪个原材料的供应商?缺乏这些追溯信息,SPC分析在面对异常波动时根本无法进行根因分析。
结构化融合:设计、检测与制造的统一
先进的数字化质量系统会在数据产生的那一刻,强制建立结构化关联模型。一条具备工程意义的质量数据记录,必须在数据库事务层面将以下三层信息进行绑定:
-
物理检测层:记录高精度的实际测量值、检测人员与时间戳。
-
设计标准层:至少要关联该特性的上下公差 (USL/LSL)、目标值。
-
制造追溯层:绑定 MES 或 ERP 中的工单号、批次号、设备 ID 与模具穴号。
这种多维数据模型的封装是运行控制图判异规则、计算 CPK/PPK 的绝对前提。
仅仅录入示例
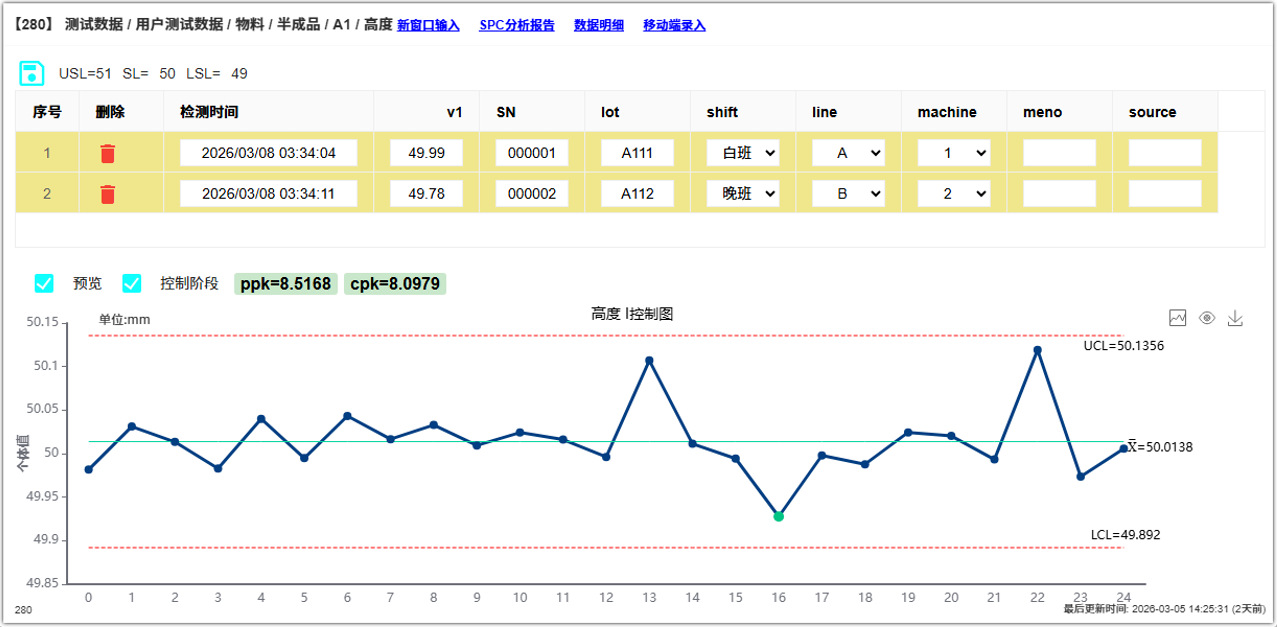
即使通过excel导入、接口同步等等,都有上述一样的可追溯的结构化数据。 如何利用结构化数据进行SPC分析(示例)
同一个检测项目,结构化数据包含了设备号,那么我们就可以区分不同设备生产的同种产品同一个检测项目的控制图和CPK PPK,如果考虑到设备的生产成本效率都差不大的情况下,那么可以 -
根据公司策略,比如把VIP客户订单安排到cpk更好的设备上生产 -
检查两台设备查找为什么CPK差异大的原因和改进。

要获取更多的示例,请和我们联系 斌果SPC如何重构底层数据底座
斌果SPC作为一款高度成熟的WEB SPC,从底层数据库架构上彻底抛弃了需要人工拼接追溯数据的单机版思维。不管是手工录入、excel导入或者接口同步,都预留足够的结构化字段来记录每一个检测值的属性元数据(如批号、班次、工位、人员、设备、模具、材料供应商等),这些都可以自定义。
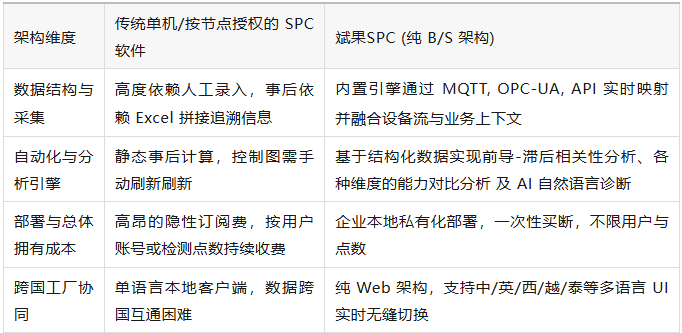
没有结构就没有自动化分析
当今的质量统计程序已演进得极为复杂。如果没有标准化的数据结构作为支撑,系统如何知道该将哪部分历史数据送入大语言模型 (LLM) 进行深度的自然语言质量诊断?
无论是自动生成多级控制图、执行实时的过程能力分析,还是通过算法识别微观的工序偏移模式,全依赖于底层数据模型中清晰的特性映射与追溯锚点。SPC 的起点绝不是统计公式,而是坚实的数据结构底座。
放弃那些吞噬预算、成本极高且容易形成数据孤岛的订阅制老旧SPC系统。
斌果SPC 助力您的质量数据底座真正具备工业 4.0 的承载力。
本页面文章与公众号同步。

微信扫码关注
-